HBase的原型是Google的BigTable论文,受到了该论文思想的启发,目前作为Hadoop的子项目来开发维护,用于支持结构化的数据存储。HBase是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。HBase是Google Bigtable的开源实现,但是也有很多不同之处。HBase利用Hadoop HDFS作为其文件存储系统,它利用Hadoop MapReduce来处理HBase中的海量数据,使用Zookeeper作为协同服务。
首先学习HBase需要搭建对应的环境,这里为了不在环境上浪费过多的时间,我采用了Docker搭建HBase的方式,使用其内置的Zookeeper以及Hadoop实现数据的操作。Docker是一个非常强大的工具,它能够非常方便的帮我们搭建出想要的各种环境,我使用Docker也有快一年的时间,也处于一个学习的状态,后期我会专门写一篇关于Docker使用的文章进行总结。今天我们来介绍一下HBase的搭建以及如何使用Java API进行访问。
使用Docker搭建HBase的环境
Docker的安装不是本篇的重点,后面会专门写一篇关于Docker使用的总结。至于Docker能安装在什么机器上,无论你是本地PC还是远程Linux服务器,Docker都能够实现安装。我使用的是Mac的环境,安装Docker Desktop即可。首先我们需要从镜像仓库中拉取HBase的镜像,使用如下的命令:
我们能够看到有以下的仓库镜像:
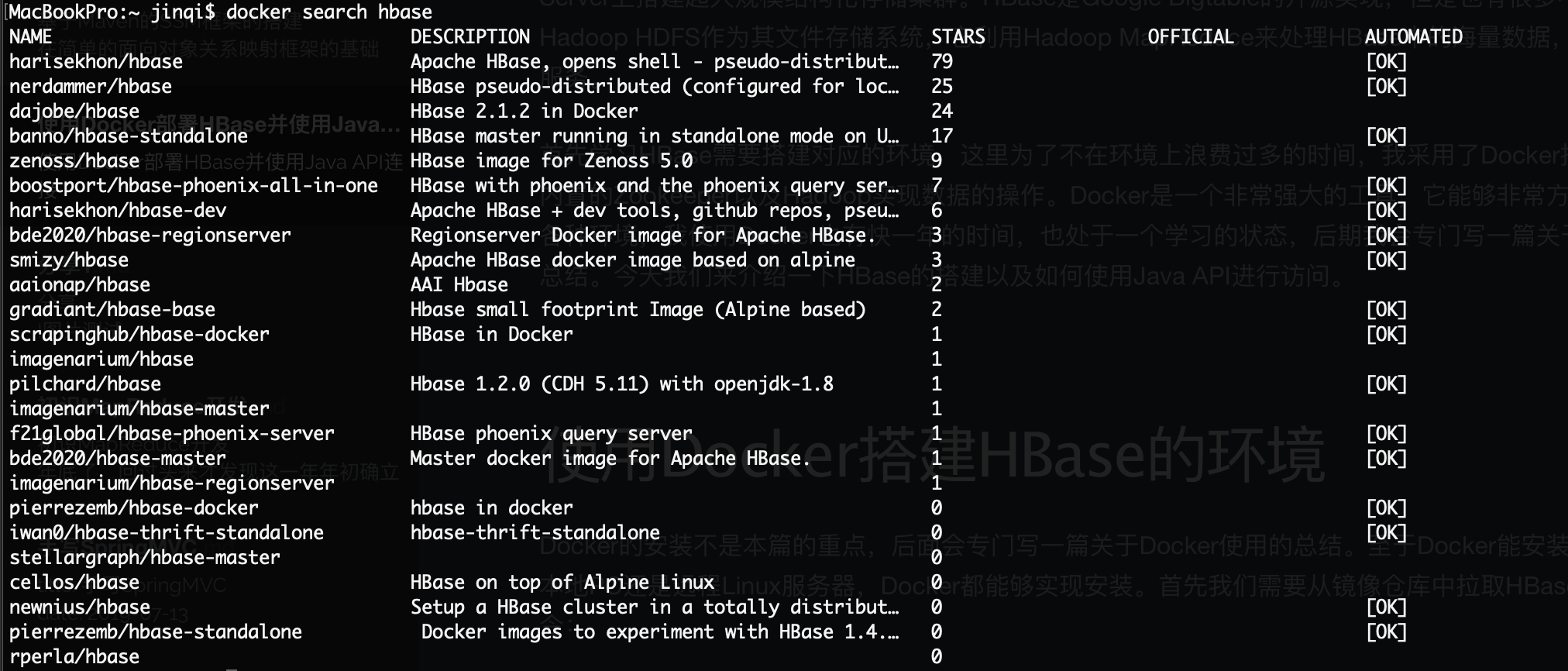
我们选择harisekhon/hbase的1.3的版本,因为是测试成功过的,使用以下命令拉取镜像:
1
| docker pull harisekhon/hbase:1.3
|
然后我们使用docker run的命令启动HBase容器,这里的命令非常重要,和设置端口号有关,与之后能不能使用Java API连接到HBase有很大的关系:
1
| docker run -d -h myhbase -p 2181:2181 -p 9090:9090 -p 9095:9095 -p 16000:16000 -p 16010:16010 -p 16201:16201 -p 16301:16301 --name hbase1.3 harisekhon/hbase:1.3
|
1
2
3
4
| -d 表示后台运行
-h 表示设置docker容器的虚拟主机名
-p 表示端口映射,冒号前是主机端口号,冒号后是外部映射端口号,其中2181是Zookeeper的端口,16010是HBase的端口
--name 表示给docker容器取名
|
然后我们使用下面的命令查看容器启动状态:

首先可以使用下面的命令进入容器内部,测试HBase能否正常使用:
1
2
3
| docker exec -it hbase1.3 bash #进入容器的bash
hbase shell #进入hbase命令行
list #查看表列表
|
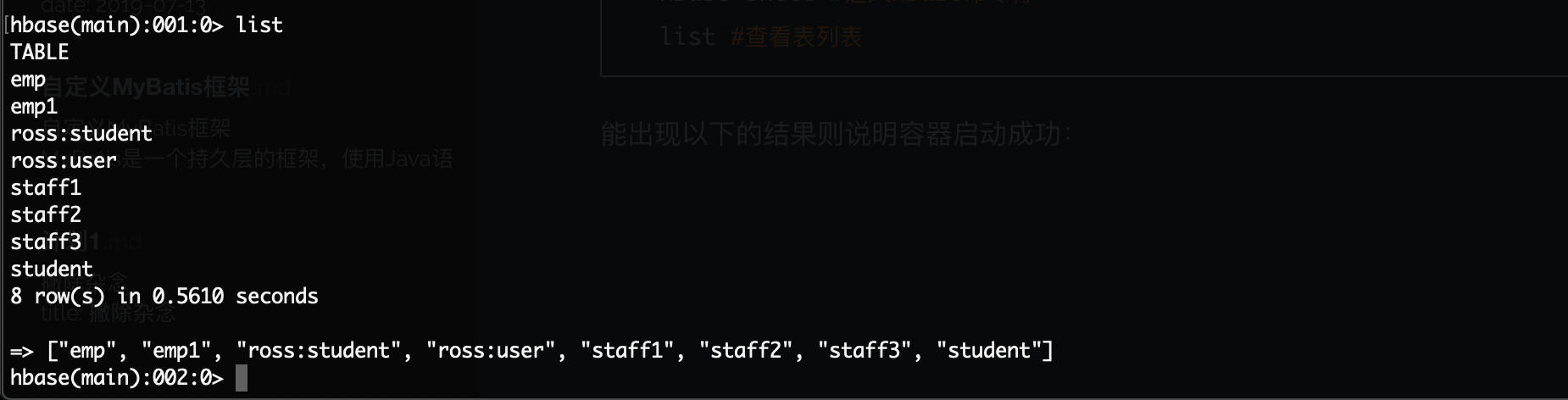
能出现以下的结果则说明容器启动成功:
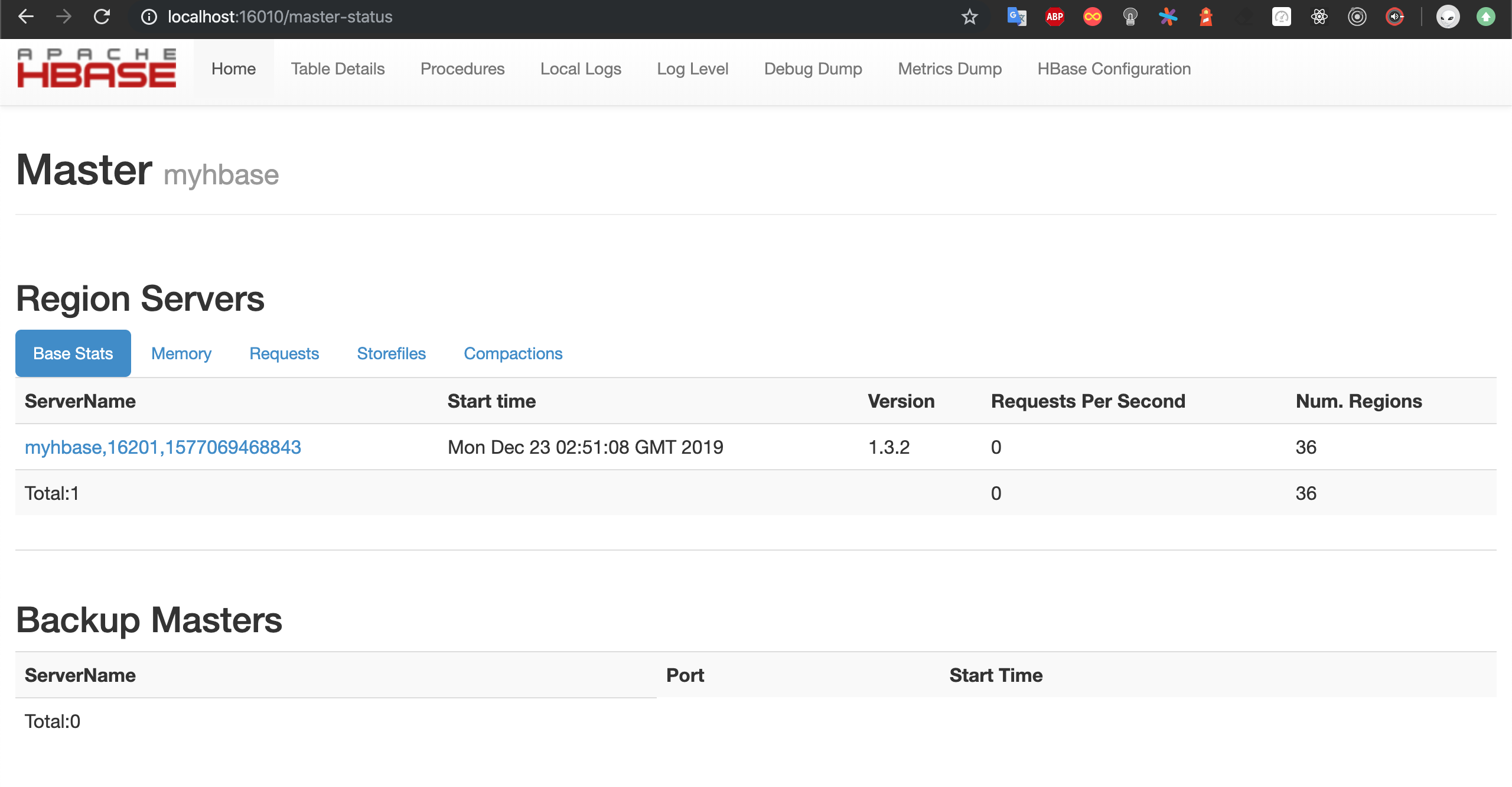
或者可以直接访问本地的16010端口查看web页面:
至此,本地的Docker搭建HBase的环境就结束了,后面我们就能使用API对HBase进行一系列的数据库操作。
HBase的概述
HBase的架构
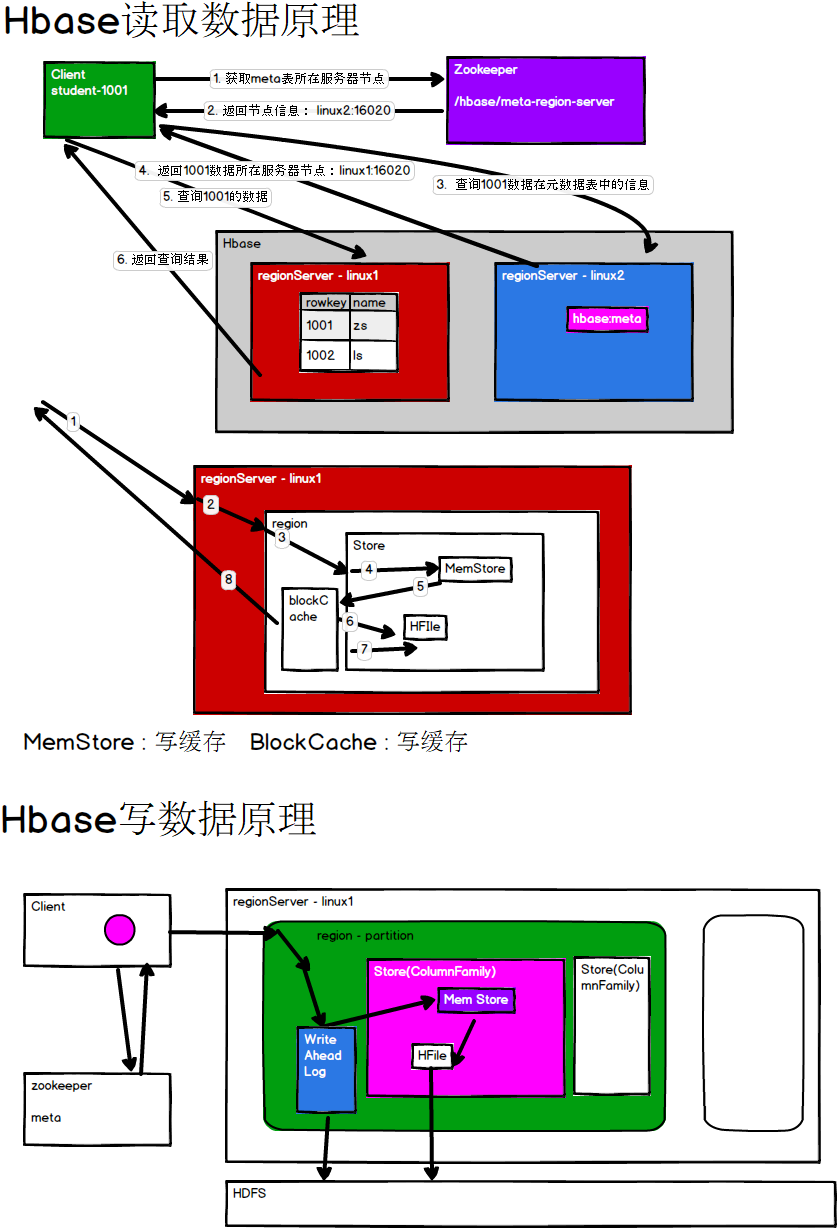
首先我们先看一下HBase的架构图:
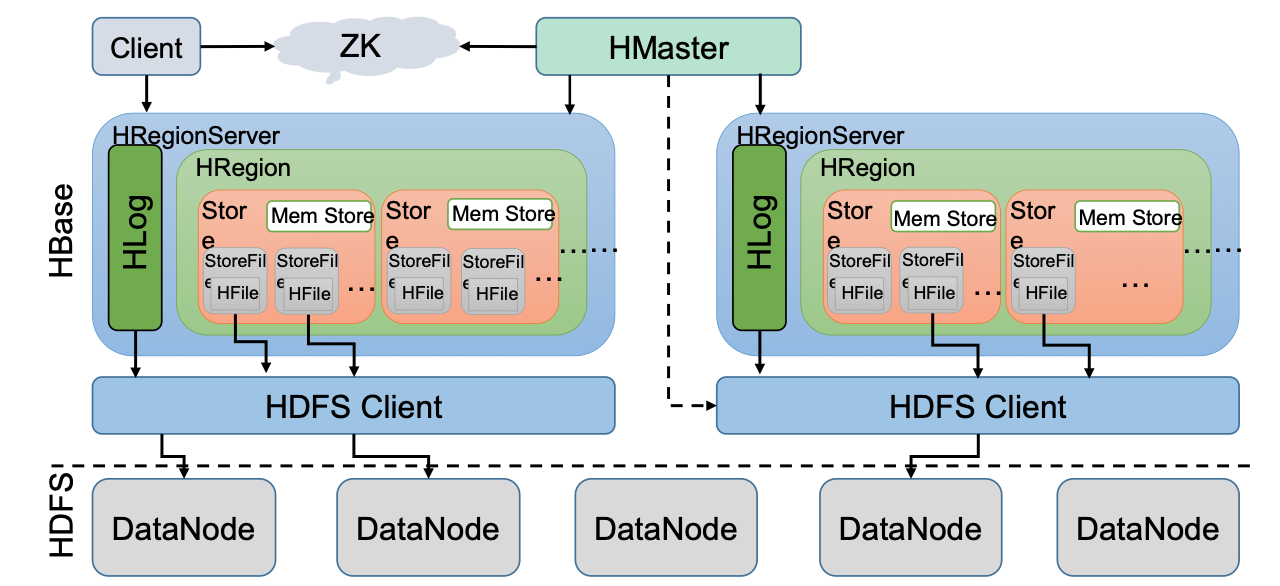
从图中可以看出Hbase是由Client、Zookeeper、Master、HRegionServer、HDFS等几个组件组成,下面来介绍一下几个组件的相关功能:
1.Client
Client包含了访问HBase的接口,另外Client还维护了对应的cache来加速HBase的访问,比如cache的META元数据的信息。
2.Zookeeper
HBase通过Zookeeper来做master的高可用、RegionServer的监控、元数据的入口以及集群配置的维护等工作。具体工作如下:
通过Zoopkeeper来保证集群中只有1个master在运行,如果master异常,会通过竞争机制产生新的master提供服务;通过Zoopkeeper来监控RegionServer的状态,当RegionSevrer有异常的时候,通过回调的形式通知Master RegionServer上下线的信息;通过Zoopkeeper存储元数据的统一入口地址。
3.HMaster(NameNode)
master节点的主要职责如下:为RegionServer分配Region;维护整个集群的负载均衡;维护集群的元数据信息;发现失效的Region,并将失效的Region分配到正常的RegionServer上;当RegionSever失效的时候,协调对应Hlog的拆分。
4.HRegionServer(DataNode)
HRegionServer直接对接用户的读写请求,是真正”干活”的节点。它的功能概括如下:管理master为其分配的Region;处理来自客户端的读写请求;负责和底层HDFS的交互,存储数据到HDFS;负责Region变大以后的拆分;负责Storefile的合并工作。
5.HDFS
HDFS为Hbase提供最终的底层数据存储服务,同时为HBase提供高可用(Hlog存储在HDFS)的支持,具体功能概括如下:提供元数据和表数据的底层分布式存储服务;数据多副本,保证的高可靠和高可用性。
附上HBase的读写数据原理图:
HBase中的角色
1.HMaster
监控RegionServer;处理RegionServer故障转移;处理元数据的变更;处理region的分配或转移;在空闲时间进行数据的负载均衡;通过Zookeeper发布自己的位置给客户端。
2.RegionServer
负责存储HBase的实际数据;处理分配给它的Region;刷新缓存到HDFS;维护Hlog;执行压缩;负责处理Region分区。
HBase中的其他组件
1.Write-Ahead logs
HBase的修改记录,当对HBase读写数据的时候,数据不是直接写进磁盘,它会在内存中保留一段时间(时间以及数据量阈值可以设定)。但把数据保存在内存中可能有更高的概率引起数据丢失,为了解决这个问题,数据会先写在一个叫做Write-Ahead logfile的文件中,然后再写入内存中。所以在系统出现故障的时候,数据可以通过这个日志文件重建。
2.Region
HBase表的分区,HBase表会根据RowKey值被切分成不同的region存储在RegionServer中,在一个RegionServer中可以有多个不同的region。
3.Store
HFile存储在Store中,一个Store对应HBase表中的一个列族(列簇,Column Family)。
4.MemStore
顾名思义,就是内存存储,位于内存中,用来保存当前的数据操作,所以当数据保存在WAL中之后,RegsionServer会在内存中存储键值对。
5.HFile
这是在磁盘上保存原始数据的实际的物理文件,是实际的存储文件。StoreFile是以Hfile的形式存储在HDFS的。
使用API访问HBase
HBase也支持shell命令进行操作数据库,进入到docker容器中然后输入hbase shell命令回车,即可进入到命令行模式,但通常我们更多的是使用API进行操作数据库,因为很多时候我们写的MapReduce就需要放在Hadoop上运行,所以掌握API操作HBase是非常重要的。
导入Maven依赖
1
2
3
4
5
6
7
8
9
10
11
12
| <dependencies>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>1.3.2</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.3.2</version>
</dependency>
</dependencies>
|
封装工具类
测试API的过程中发现每次连接HBase都需要配置连接信息,还有关闭资源这些操作,就想到将他们封装成一个工具类,其中还包含了生成分区键和分区号的方法,采用了和Map存放类似的生成hash码的方式。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
| package com.jinqi.util;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
public class HBaseUtil {
private static ThreadLocal<Connection> connHolder = new ThreadLocal<Connection>();
private HBaseUtil() {
}
public static void makeHBaseConnection(String hostName,String post) throws IOException {
Connection conn = connHolder.get();
if (conn == null){
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", hostName);
conf.set("hbase.zookeeper.property.clientPort", post);
conn = ConnectionFactory.createConnection(conf);
connHolder.set(conn);
}
}
public static byte[][] genRegionKeys(int regionCount){
byte[][] bs = new byte[regionCount-1][];
for (int i = 0; i < regionCount - 1; i++) {
bs[i] = Bytes.toBytes(i+"|");
}
return bs;
}
public static String genRegionNum(String rowKey,int regionCount){
int regionNum;
int hash = rowKey.hashCode();
if (regionCount > 0 && (regionCount & (regionCount -1)) == 0){
regionNum = hash & (regionCount - 1);
}else {
regionNum = hash & (regionCount);
}
return regionNum + "_" + rowKey;
}
public static void insertData(String tableName,String rowKey,String family,String column,String value) throws IOException {
Connection conn = connHolder.get();
Table table = conn.getTable(TableName.valueOf(tableName));
Put put = new Put(Bytes.toBytes(rowKey));
put.addColumn(Bytes.toBytes(family),Bytes.toBytes(column),Bytes.toBytes(value));
table.put(put);
table.close();
}
public static void close() throws IOException {
Connection conn = connHolder.get();
if (conn != null){
conn.close();
connHolder.remove();
}
}
}
|
连接、插入数据测试:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| package com.jinqi.hbase;
import com.jinqi.util.HBaseUtil;
import java.io.IOException;
public class TestHbaseAPI3 {
public static void main(String[] args) throws IOException {
HBaseUtil.makeHBaseConnection("myhbase", "2181");
HBaseUtil.insertData("ross:student", "1003", "info", "name", "jinqi");
HBaseUtil.close();
}
}
|
查询数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
| package com.jinqi.hbase;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.filter.*;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
public class TestHbaseAPI4 {
public static void main(String[] args) throws IOException {
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "myhbase");
conf.set("hbase.zookeeper.property.clientPort", "2181");
Connection connection = ConnectionFactory.createConnection(conf);
TableName tableName = TableName.valueOf("student");
Table table = connection.getTable(tableName);
Scan scan = new Scan();
BinaryComparator bc = new BinaryComparator(Bytes.toBytes("1002"));
RegexStringComparator rsc = new RegexStringComparator("^\\d{5}$");
Filter filter = new RowFilter(CompareFilter.CompareOp.EQUAL,rsc);
RowFilter rowFilter = new RowFilter(CompareFilter.CompareOp.EQUAL,bc);
FilterList list = new FilterList(FilterList.Operator.MUST_PASS_ONE);
list.addFilter(filter);
list.addFilter(rowFilter);
scan.setFilter(list);
ResultScanner scanner = table.getScanner(scan);
for (Result result : scanner) {
for (Cell cell : result.rawCells()) {
System.out.println("rowKey=" + Bytes.toString(CellUtil.cloneRow(cell)));
System.out.println("family=" + Bytes.toString(CellUtil.cloneFamily(cell)));
System.out.println("column=" + Bytes.toString(CellUtil.cloneQualifier(cell)));
System.out.println("value=" + Bytes.toString(CellUtil.cloneValue(cell)));
}
}
table.close();
connection.close();
}
}
|
简单API的操作已经介绍完了,但通过HBase的相关Java API,我们可以实现伴随HBase操作的MapReduce过程,比如使用MapReduce将数据从本地文件系统导入到HBase的表中,比如我们从HBase中读取一些原始数据后使用MapReduce做数据分析,这些内容我们会在后面的文章中总结。
